Building the Crossword Builder
My crossword builder is essentially composed of two major parts: the frontend and the backend. The frontend is in JavaScript, while the backend is written in Go. In this post I’ll talk about how each side works, and how the two communicate with each other.
Overview
The high level view of the system is fairly straight-forward, with the user interacting with the frontend via the browser, and the frontend, running in the browser, interacting with the backend over a websocket. The overall flow is basically the same as for the sudoku solver, which I have covered in an earlier post:
sequenceDiagram
participant User
participant Browser
participant Backend
User->>Browser: Presses "Auto-fill" button
Browser->>Backend: Start solving
loop Solving
Backend->>Browser: State updates every 100ms until solved
end
note over Browser,Backend: Communicate over a websocket
The frontend is written in TypeScript, and is where all the smarts live for building a crossword grid, seeding it with a few words and all kinds of user-facing validation. The frontend takes care of tracking state via URL parameters, including the requisite encoding and decoding. More on these later.
The backend is where all the combinatorial optimization happens, to solve a given crossword puzzle. The backend expects the frontend to provide a valid grid, possibly pre-filled with some words; its task is then to find how to fill this grid in, all the way. Since this search for a valid solution to the crossword may take a while, I thought it would be interesting to present in-progress state back to the caller, as search goes on. Websockets are used to pass this data back to the frontend.
Before getting into the details I’ll first mention a few self-imposed requirements on the overall system:
- It’s a hobby project of mine, and while I find writing the code for this therapeutic (as in “I don’t have time to write code for work anymore and this is my outlet”), I want to push the limits of what I can do within freebie limits of Google Cloud. So I needed to keep this computationally tractable for the E2 micro VM, and avoid excessive storage and network traffic.
- In part for the same reason, and in part to avoid losing data, I want to keep the backend stateless.
- I want to make it easy to share the crossword puzzles.
- While I do want to optimize things where it is sensible to, I don’t want to sacrifice too much just for the sake of speed. Particularly, I want the code for the most complex part of the project be in Go, rather than see how far I can stretch things with TypeScript. I just don’t love TypeScript and its tool chain enough…
Frontend
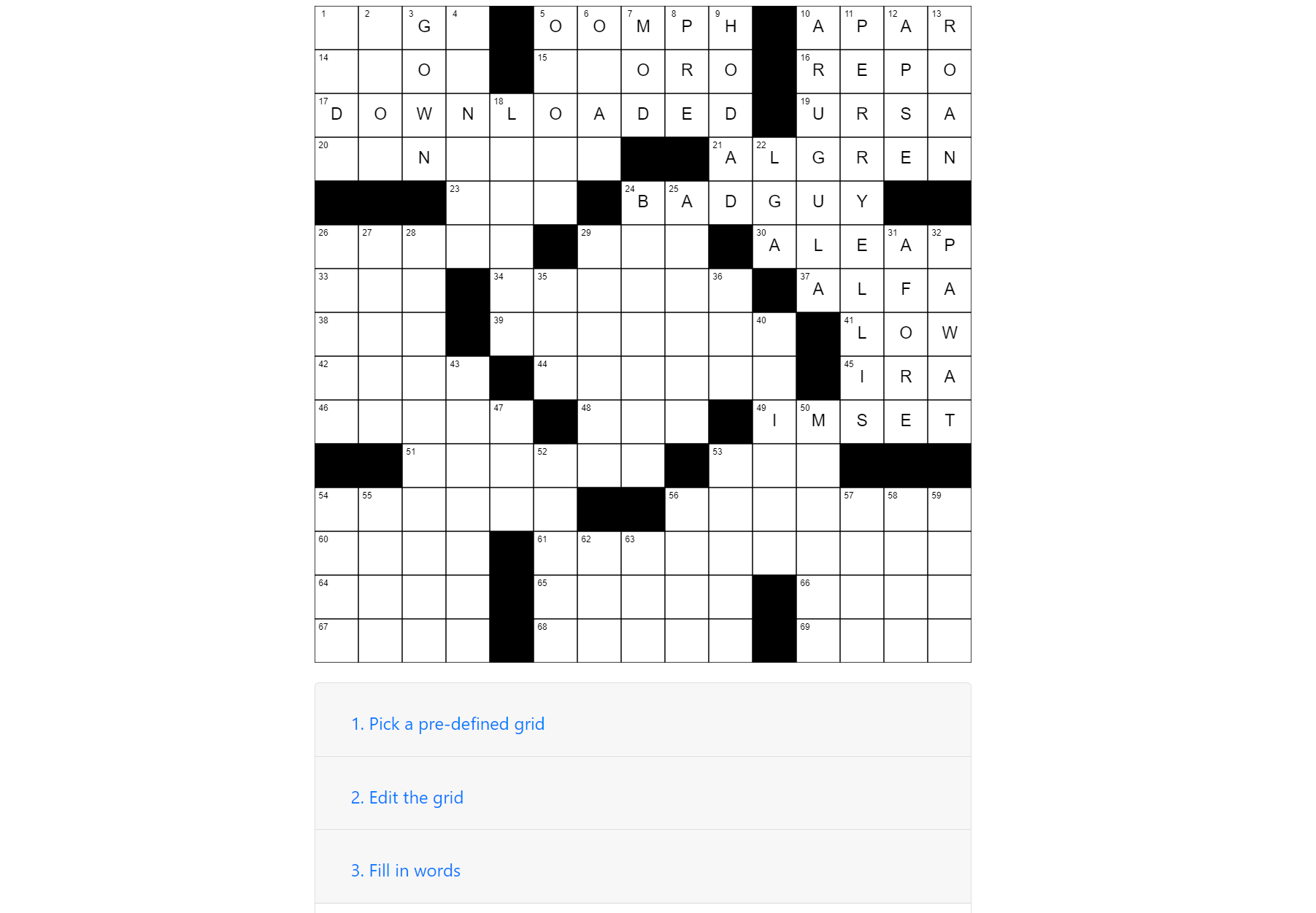
The frontend has a few key responsibilities, which line up with the steps you might’ve seen on the UI:
- Setting up the grid. The current version breaks this up into two parts: picking a starting grid from one of the presets, and modifying it to your heart’s content. As the grid is filled the relevant info is updated, like the word labels on the grid, and the word stats. These can be useful, as crossword publishers often have requirements about how many words a puzzle should have.
- Filling the grid. This step can also be viewed as two separate kinds of actions: letting the user add their own words to the grid, and letting the user auto-fill the grid for the rest. Importantly, this auto-fill step is the only step where backend interaction happens, as the rest is all done on the frontend.
- Filling the clues and printing/saving. This is the last step where the user can take their fully filled in grid and associate each of the words with clues. The user can then print or save their creation to a PDF file.
The above are achieved as follows:
- A good old
canvasis used as the main UI surface, with basic listeners for key / mouse / tap events. - The UI behaves differently depending on which step the user is on, to name a couple of key behaviors:
- When “Edit the grid” is selected, clicking on the grid will toggle that cell as a fillable / blocked cell, followed by triggering grid validation
- When “Fill in words” is selected, clicking on the grid will allow the user to start populating the grid with letters + words, which also triggers validation. This time though, validation applies to words rather than the grid itself, as incomplete words are disallowed
- On the code level this is achieved by having a few key objects to represent the grid itself, words, clues, and so on. Most of the interactions, primarily from the
canvas, are delegated to the relevant objects.
One interesting bit here is that I initially tried to flesh all of this out in pure JavaScript, but as the complexity grew, I ended up biting the bullet and moving this logic over to TypeScript. That was the right choice as it allowed me to properly cover key functionality with tests, as well as cleanly separate what was becoming an entangled mess of JavaScript code. I’m not an expert in either JavaScript or TypeScript though, so I won’t claim that this was the only way to solve that problem, it’s just one that worked for me.
As mentioned above, the “Auto-fill” button on the UI is the one that triggers the actual combinatorial solving on the backend. I’ll talk about the protocol between the frontend and the backend separately. For now, let’s touch on how state is kept, as this also impacts how state is shared with the backend.
State
State is primarily a frontend concern in my design, as the backend is stateless. As I mentioned earlier, one of my self-imposed requirements is to make that the generated puzzles could be sharable, and one way to achieve this, and tracking state, is just to cram the state into URL parameters, which is exactly what I’ve done:
gridencodes the blank / blocked squares. The puzzle assumes a certainsize(which you can override on UI, but backend will reject puzzles larger than 15x15) that together withgridtell the UI what the empty puzzle is. I used a basic binary representation forgridwhere each square corresponds to a bit, and the entire thing is converted to a base-64 string. This results in a fairly compact way to represent empty grids. Here’s the code (the corresponding translation in the opposite direction is similar and is omitted):
function b64FromTemplate(t: Template): string {
var bi = BigInt(0);
for (var y = 0; y < t.size; y++) {
for (var x = 0; x < t.size; x++) {
bi = bi * bigTwo;
var p = new Point(x, y);
if (t.isBlocked(p)) {
bi = bi + bigOne;
}
}
}
return bnToB64(bi);
}stateencodes the words supplied by the user. Here, I didn’t bother optimizing for terseness, as generally speaking users will only manually enter a few words, and so the format of this one is fairly straight-forward, demonstrated by the relevant chunk of code below:
getWordsAsStateString(fixedWords: Word[]): string {
var words = "";
fixedWords.forEach(word => {
var wordName = zeroPad(word.num, 2) + (word.direction == across ? "-across" : "-down");
var wordState = this.getWordValue(word);
words += `${wordName}=${wordState};`;
});
return words;
}allencodes all of the words, including those generated by auto-filling. This one is a bit more likegridin that it enumerates all the blank (i.e., non-blocked) grid cells and for each blank cell tucks on the new letter on a base-26 big-int, which is converted to a base-64 string:
getAsB64(): string {
var size = this.blanks.size;
var bi = BigInt(0);
for (var y = 0; y < size; y++) {
for (var x = 0; x < size; x++) {
var p = new Point(x, y);
if (this.blanks.isBlocked(p)) {
continue;
}
bi = bi * bigTwentySix;
bi = bi + BigInt(this.get(p)!.charCodeAt(0) - aOffest);
}
}
return bnToB64(bi);
}These allow me to track state without storing it anywhere other than URL parameters. Here’s an example. Breaking this down into pieces:
gridis set toEEAggEEAAhxEQRAIABEQACARBERwgAEEAggEEA%3D%3D, encoding the blank / blocked cells,stateis set to45-across%3Dcat%3B(45 across is “cat”),allis the rather beefy string encoding the rest of the grid (snippet included, see URL for the full thing):DORCclsKasQYWMBlkEo7oGe8WOSuQFzlTk8S1tiL...
The above results in the following crossword: 
Note: clues are not stored yet. These will be even more beefy than
all, so I’m entertaining the idea of compressing them before putting them into URL parameters, or looking for other means to store puzzle state. For now, one can “Save” or print the puzzle and its clues.
Backend
At the most basic level, the backend has one responsibility1 - auto-fill the puzzles provided by the frontend. A bit more specifically, the frontend will specify the following:
grid, as described above,size, which defaults to 15 (and 15 is the maximum allowed),longer, which is a boolean that allows the user to pick the longer word list,state, as described above (may be empty).
The backend will accept these, do its own validation (like rejecting instances where size > 15, so that my poor E2 micro VM instance doesn’t blow up), model the crossword as a constraint satisfaction problem (CSP) and then stream search progress over the websocket back to the frontend. Let’s take a look at how this CSP is constructed.
Basic CSP structure
While the UI itself has a bit of complexity of its own, the bulk of complexity lies in the solver that auto-fills the crossword puzzle. To do this, the solver converts the inputs above into a CSP:
- Variables - in this case, we will associate each crossword entry, like 5-across, with a variable.
- Variable domains of such variables are the possible words from the dictionary that such a crossword entry can take. Here the word length is the only thing that matters, so if the crossword entry is 5 letters long, the domain of its variable is all dictionary words of length 5.
- Constraints - there are two key types of constraints in a crossword:
- All different constraint states that we will only use a given word from the dictionary at most once. We’ll only need one for the entire puzzle, but if you want to get to the nitty-gritty level, it’s a bit more efficient to have one all-different constraint per possible word length.
- Overlap constraints state that overlapping words (across and down) must have the same letter in the cell that they overlap on. For example, in the filled crossword above we can see that 1-across is “ABAC” and 1-down is “ATAT” - the two words overlap on the first letter, which happens to be “A”. There will be many constraints of this type, to enumerate all overlaps.
As always, the goal of solving a CSP is to find an assignment to all variables such that none of the constraints are violated. In our case this means choosing words to assign to each of the crossword entries, and the constraints will ensure that no overlapping words disagree, and each word is used at most once.
The idea is then that the user will specify:
gridandsizeto define the overall puzzle structure and thus the variables,longerto tell us which dictionary to use, which will inform the variables’ domains,stateto lock a few of the variables in to the values that the user provided (we won’t check if these belong to the dictionary and take them for granted).
The trickiest bit is making this efficient, because solving a CSP may mean visiting millions of states, and so we need to ensure that constraint evaluation is quick. I’ve written at some length about all-different constraints and its different implementations, so here I’ll just mention that the Sparse implementation tends to be the best fit for crosswords, because it is fast to evaluate and works well when there are few variables with large domains, which is exactly the case for crossword puzzles. The overlap constraint is more interesting here, in that, unlike all-different constraint which is generic, this one is special-purpose. So let’s dig into this one.
Overlap constraint
An overlap constraint will apply to a specific overlap between a pair of words, and its structure is basically this:
type overlapConstraint struct {
// Variables for crossword entries.
firstVar, secondVar *model.Variable
// These store basic info (X, Y, Number, Length) about the crossword entries.
firstWord, secondWord Word
// 0-based letter offset into the respective words.
firstOverlapOffset, secondOverlapOffset int
// Dictionary.
words *Words
}The key bit to making this constraint efficient is being able to determine whether this constraint supports the assignment of a new value to one of its variables. In my model this means implementing the following (a few details are omitted for brevity):
func (oc *overlapConstraint) Supported(supV *model.Variable, supVal int) bool {
// Grab relevant info for the other variable.
otherV := oc.firstVar
otherOffset := oc.firstOverlapOffset
otherLength := oc.firstWord.Length
if supV == oc.firstVar {
otherV = oc.secondVar
otherOffset = oc.secondOverlapOffset
otherLength = oc.secondWord.Length
}
// Find the actual character on which the two words/entries overlap.
supChar := oc.overlappingCharacter(supV, supVal)
// Now see if any of the words in the other variable's live domain have a word
// with that character in the overlapping cell.
possibleWordValues := oc.words.MatchingWords(otherLength, otherOffset, supChar)
supported := false
otherV.LiveDomain().ForEachValue(func(value int) bool {
if possibleWordValues[value] {
supported = true
return false
}
return true
})
return supported
}That’s somewhat dense, so a few clarifications are in order:
supVandsupValrefer to the variable and value that were just assigned by search,otherVand the rest ofother*refer to the other variable in scope of this constraint,oc.words.MatchingWords()returns a precomputed list of words that are of lengthotherLength, and havesupCharappearing atotherOffset,- The idea is then that as we assign
supVwe want to make sure thatotherVhas at least one value (word from the dictionary) that it can still choose. If it does not, the search will need to try something else.
Note:
MatchingWordsgenerates all possible lists once, when the problem is constructed. This results in a larger memory footprint and some up-front cost to generate these lists, but makes the evaluation ofSupportedfunction above quicker.
And now that we’ve defined all the variables, their domains, and all of the constraints, we can rely on the CSP engine to search for a solution. As the search for a solution progresses we will send the latest state back to the frontend via the websocket. With that, let’s touch on the protocol between the frontend and the backend.
Protocol
The protocol between the frontend and the backend is trivial - I push a size x size byte array containing the grid from the backend to the front at a set cadence (100ms). The frontend then does the trivial interpretation and renders it on the UI. Here’s the bit of code that generates these messages on the backend:
func (c *CrosswordClient) convertState(state map[*model.Variable]int) []byte {
grid := problem.CrosswordStateToGrid(c.crossword, c.words, c.problem, state)
r := make([]byte, c.crossword.Size*c.crossword.Size)
for x := 0; x < c.crossword.Size; x++ {
for y := 0; y < c.crossword.Size; y++ {
idx := x + y*c.crossword.Size
r[idx] = grid[x][y]
}
}
return r
}The above is computationally cheap, but uses a bit more bandwidth than a more condensed/compressed solution might. That being said, 15x15=225, so we’re looking at only 2.25KB/s, which is small enough not to care.
Summary
In this post I’ve described how I’ve bolted together a frontend and a backend to create the crossword builder, along with they requirements and responsibilities that I’ve assigned to each, and the basic protocol between the two. I’ve spoken at some length about what the frontend is like, and in a bit of detail about how the backend solves these problems by modeling them as CSPs. If you’re interested in learning more about the CSP solver itself, check out my other posts on the subject.
This post ended up rather long, so I’ve left out a few important, but separable things, relating to the backend and keeping it reliable, plus a few tidbits about how the site is deployed. I might write more about those another time, and, if you’ve made it this far, thanks for reading!
-
This is a slight lie, in reality the backend is also responsible for hosting the website itself. ↩︎