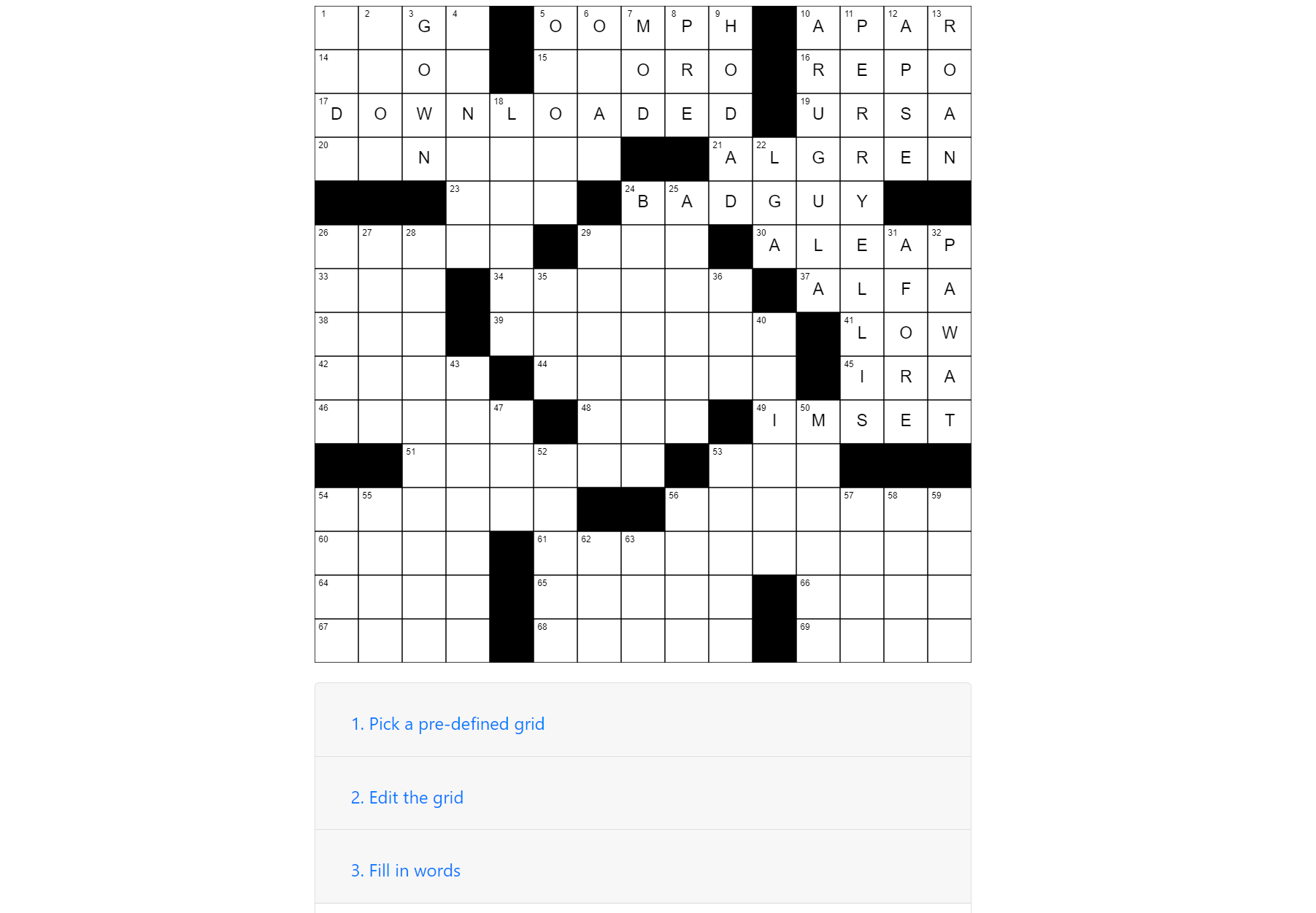
Rubber duck debugging is a well known debugging technique - it boils down to explaining the code to a rubber duck, whether a real one, or a coworker who unwittingly becomes the “rubber duck”. Halfway through the explanation the “Wait … what?” moment pops up, you know where the bug is and you run off to fix it, potentially leaving your coworker wondering why you just ran off mid-sentence.
There are plenty of articles that talk about rubber duck debugging in detail, but why should this neat technique be restricted to just debugging? I’ll explore one area in particular - applying this technique as a means to improve existing code and design, rather than just for debugging.